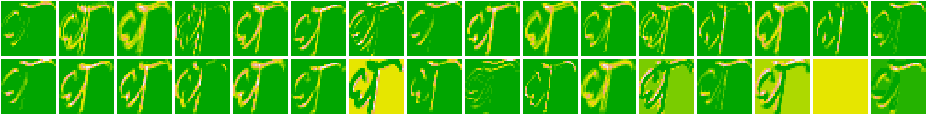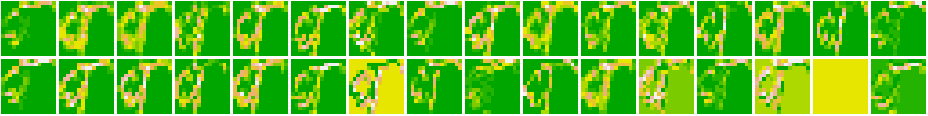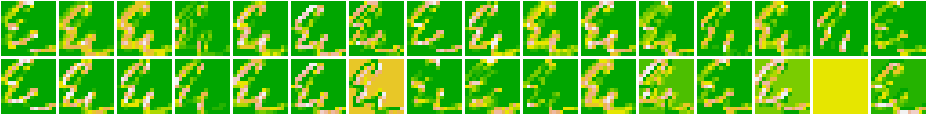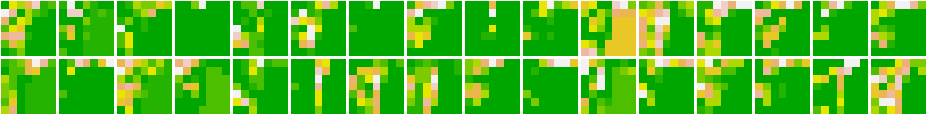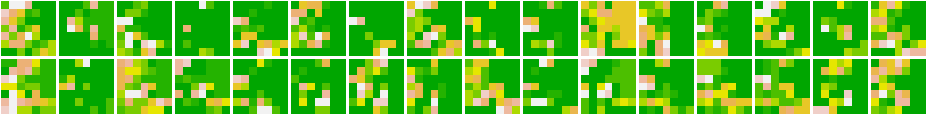Here, we apply CNNs to classify Hindi Handwritten Characters and Digits !
A Multi-Class Balanced Image Classification
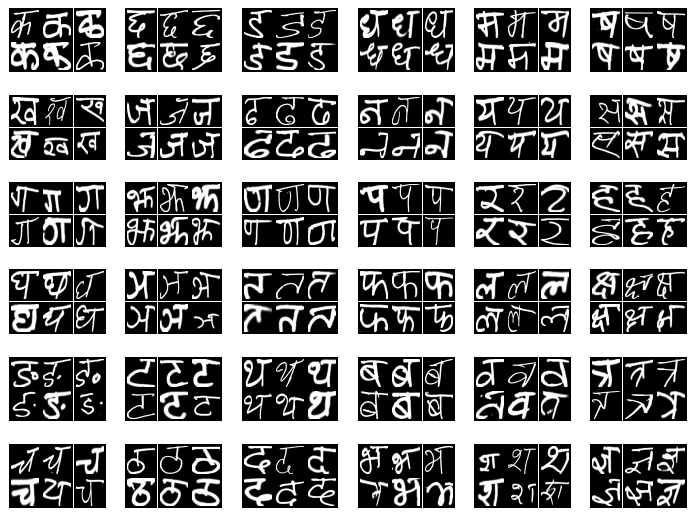
Glimpse into our Data
Figure : 36 Hindi Characters
Figure : 1-9 Hindi Digits
Data Preparation
Train-Validation-Test Split
Original Data
Total
Train
Validation
Test
character_1
2000
1400
300
300
character_2
2000
1400
300
300
…
…
…
…
…
digit_9
2000
1400
300
300
Total
92,000
63,000
13,500
13,500
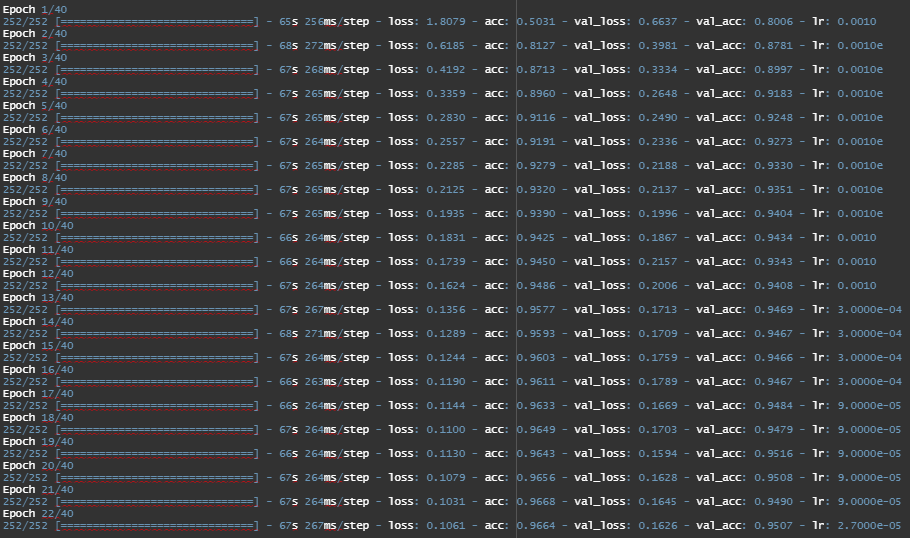
There are 36 characters and 9 digits resulting in 45 classes. This is a Balanced Multi-class Classification Problem. Based on the above split, we can use batch_size = 250. This results in steps_per_epoch = 252 for training and 54 for validation and testing.
Setting Directory
Code
original_dataset_dir ="C:/Users/KUNAL/Downloads/#R coding/#Books/covered/#Book - Manning - Deep Learning with R and Keras/## Article"base_dir ="C:/Users/KUNAL/Downloads/#R coding/#Books/covered/#Book - Manning - Deep Learning with R and Keras/## Article/HindiCharacter"train_dir =file.path(base_dir,"Training")validation_dir =file.path(base_dir,"Validation")testing_dir =file.path(base_dir,"Test")
As we can see that the first layer seems to act as an ‘edge-detector’ picking up the structure of characters and digits. As we move towards the higher layers, the representations start becoming more and more abstract. We also see that there are spaces where there were no activations at all - indicating the absence of certain filters.
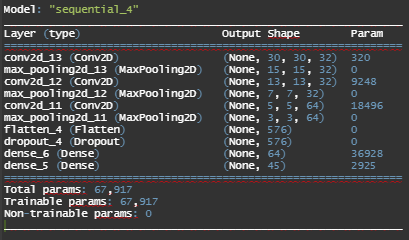
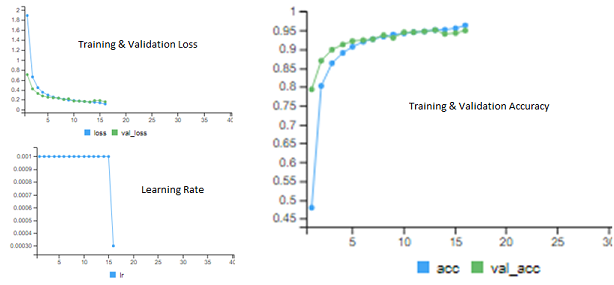
We see that Model 7 with 3 convolution layers with filters 32,32,64 kernel 3x3, pool size 2x2 with strides of 2x2 for all layers and 50% dropout layer followed by a dense classifier with 64 neurons is the best performing model with Test Accuracy = 97.84%.